


Agent 跑了 3 小时,花了 $12。
失败了,不知道哪一步跑偏;
成功了,也不知道哪一步做对。
下次换模型、改 prompt、加 tool,
效果变好还是变坏,没人说得清。
这已经不是 prompt tuning 的问题,
而是 harness engineering 的问题。
固定同一个任务和同一个模型(deepseek-v4-pro),只替换 Agent 产品侧的 Harness:
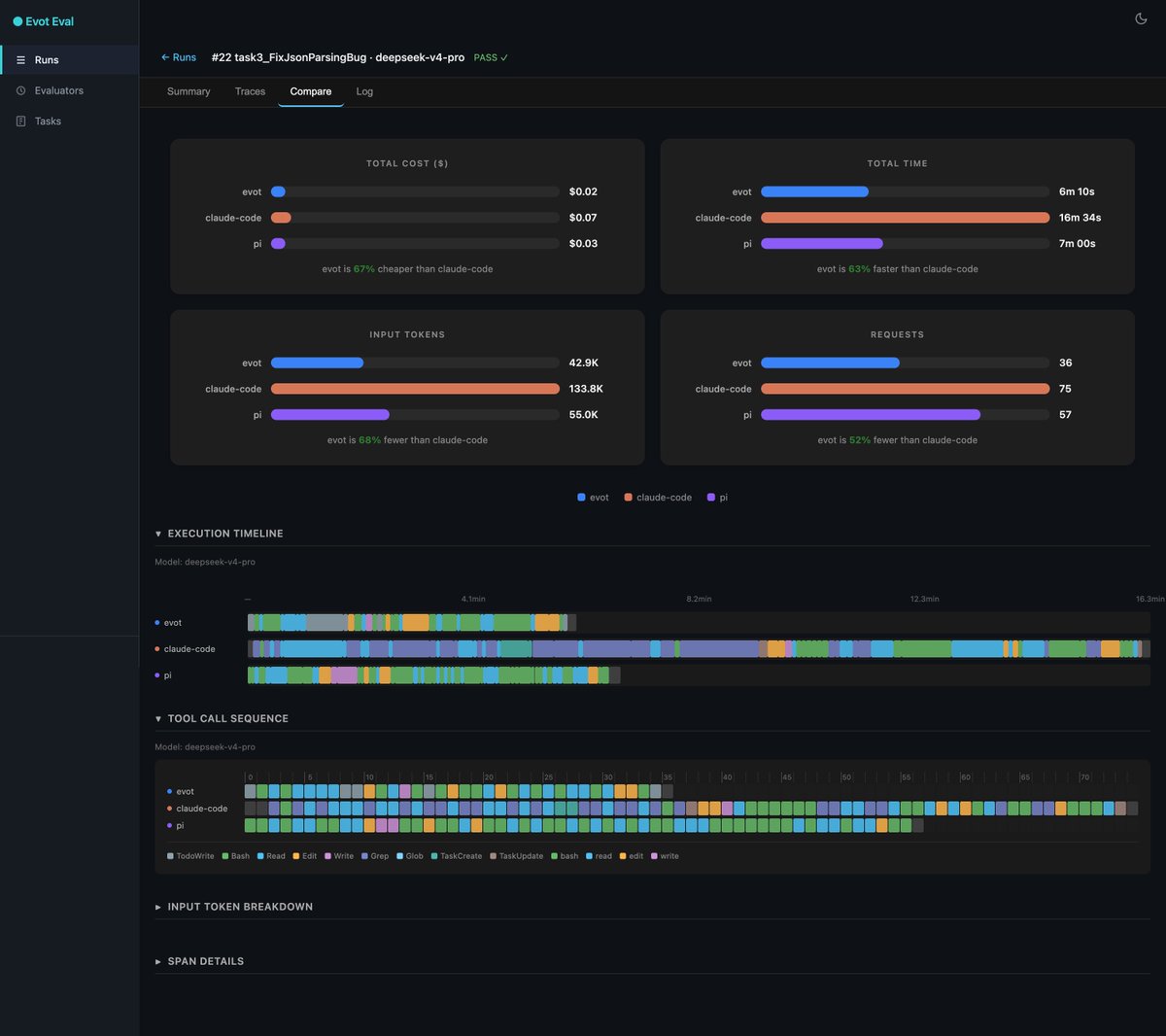
· 成本:evot $0.02 vs claude-code $0.07(便宜 67%)
· 耗时:6m10s vs 16m34s(快 63%)
· Token:42.9K vs 133.8K(少 68%)
· 调用次数:36 vs 75(少 52%)
一次 tool 选择、一次上下文裁剪、一次错误恢复,都会改变后续所有步骤。展开 trace 后会发现,差异从 tool call 序列就开始了:

试一下?
Databend 正在支撑头部大模型公司的数据底座
辅助 Agent 评测、轨迹归因与 RL 数据管线 · 日均几百 TB 级写入 · 全量 Agent 轨迹持久化

国内 · databend.cn
全球 · databend.com
GitHub · github.com/databendlabs/databend ★ 9.3k stars
 微信公众号
微信公众号